Before we formally step into this brutal battlefield named "Memory", we must first conduct a profound strategic review for this report.
In the preceding Chapter Two (2-1 to 2-7), we witnessed the pinnacle of human engineering. We utilized ASML's $200 million Extreme Ultraviolet (EUV) lithography; we fashioned transistors into suspended Gate-All-Around (GAA) structures; we even 'opened up' wafers, drilling holes from the backside for power delivery (BSPDN).
We pushed the limits of physics to finally create the world's most powerful and fastest "V12 supercar engine (logic chips CPU/GPU)" for the AI era.
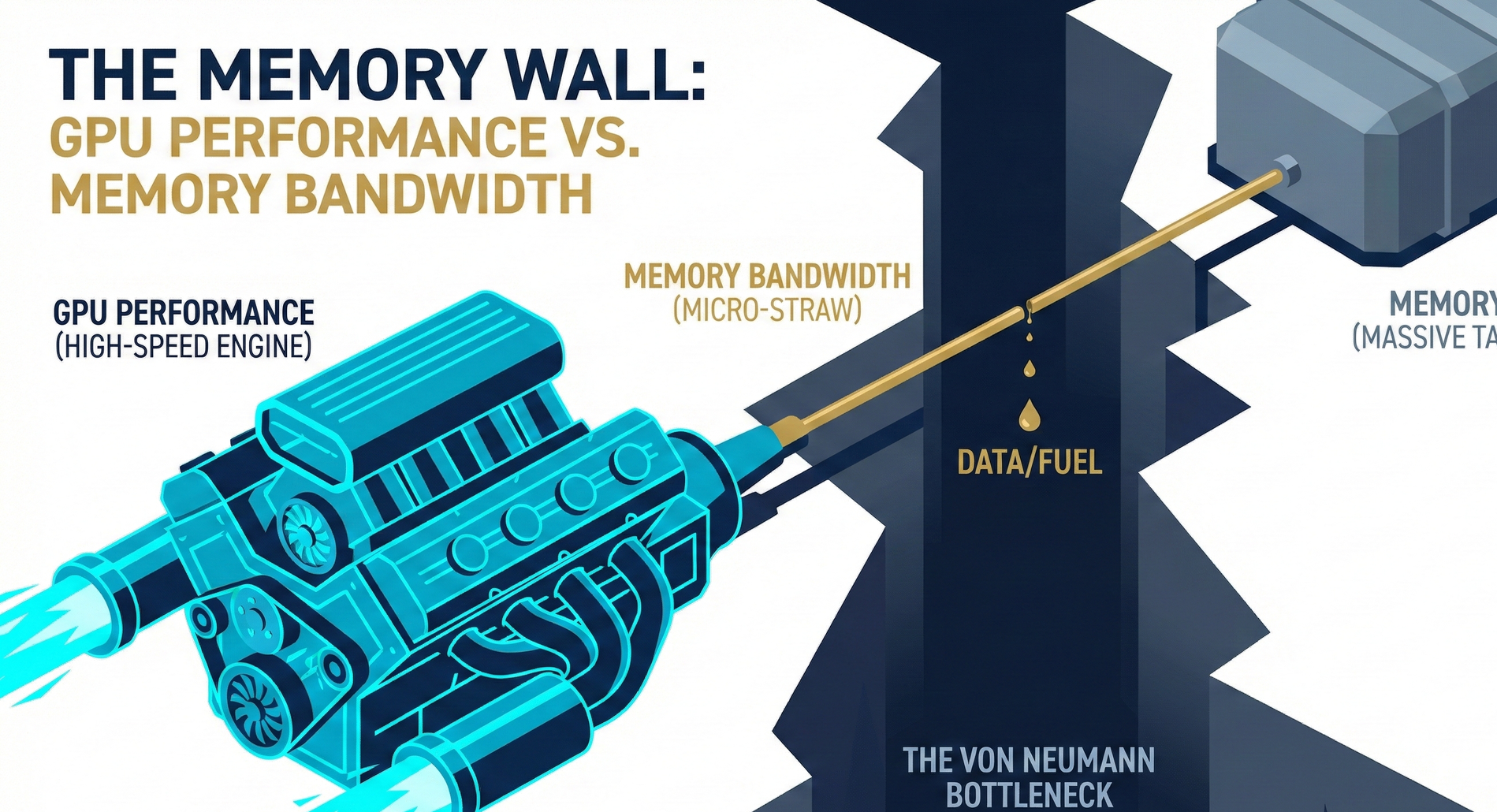
However, now, Wall Street investors and chip architects, looking at this perfect engine, have fallen into deep despair. Because they discovered a fatally absurd reality: this engine revs at 10,000 RPM, but the "fuel line" responsible for supply is a hair-thin straw, like something from a 1990s classic car, capable of dripping only one drop of oil per second.
No matter how powerful the engine, without fuel, it can only idly spin. In the field of computer science, this has been known for 70 years as a historical curse: the "Von Neumann Bottleneck". In the industry, we call it the suffocating "Memory Wall."
🧱 Chapter One: The Curse of History — Why Is There a Wall?
To understand the desperate struggle of memory manufacturers (SK Hynix, Samsung, Micron) that lies ahead, we must first understand how this wall was built.
The underlying logic of modern computers is built upon the "Von Neumann architecture" proposed in 1945. This architecture has a core principle: the "computational brain responsible for thinking (CPU/GPU)" and the "storage repository responsible for memory (DRAM/NAND)" must be two physically separate and independent components.
Since they are separate, when the brain needs to compute, it must dispatch someone to the storage repository to retrieve the "data."
💡 Investor's Plain Language Analogy: A Michelin Three-Star Chef and a Very Slow Waiter Imagine an NVIDIA GPU, manufactured by TSMC, as a "Michelin Three-Star Chef" capable of extreme knife skills. He can chop 10,000 onions per second. Traditional memory (DRAM) is like the "large ingredient warehouse" in the back. The memory bus connecting the two is the "waiter" responsible for running errands between them.
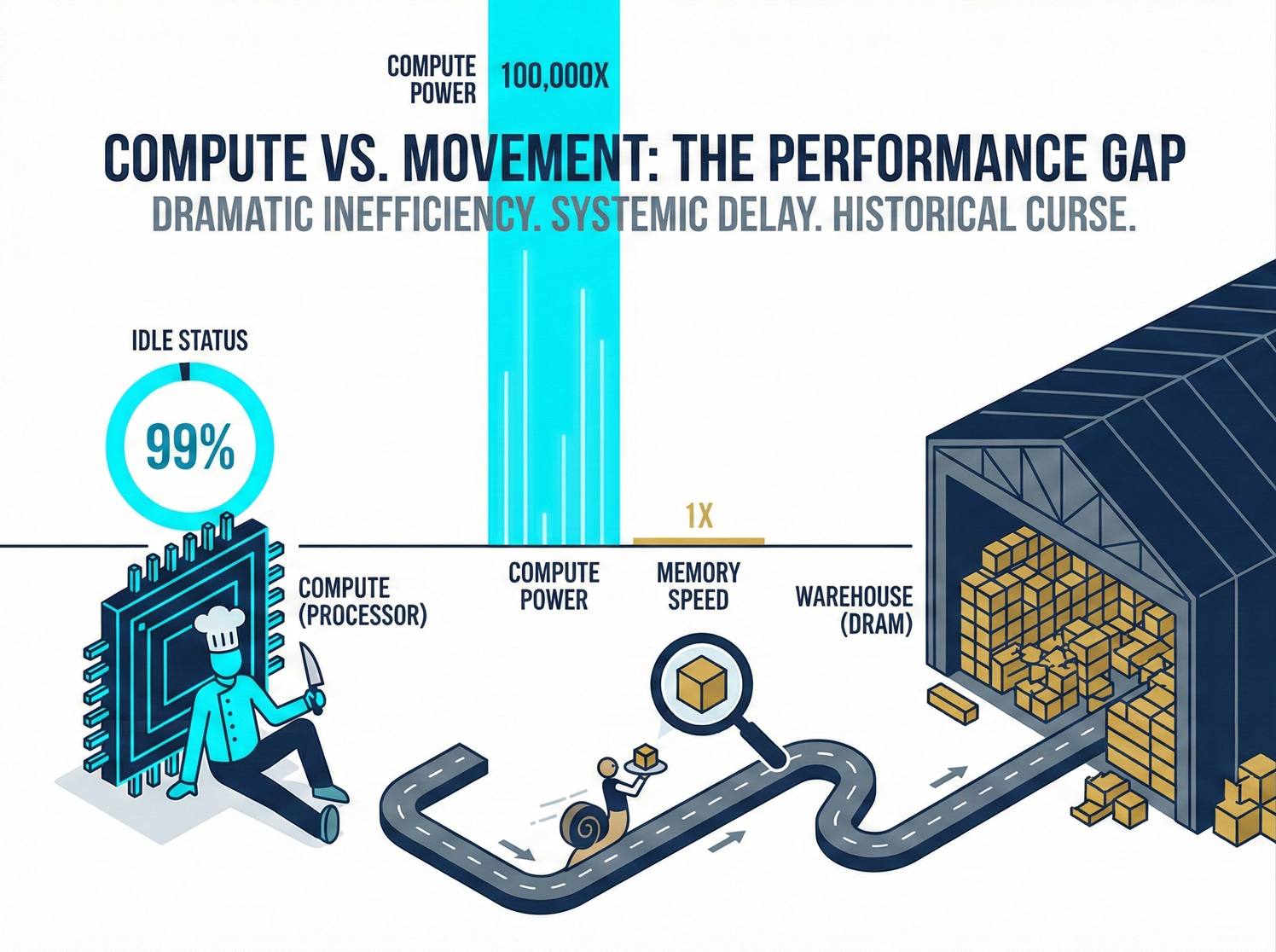
The tragedy unfolds: The chef's onion-chopping speed doubles every two years (Moore's Law); however, the waiter's walking speed has barely improved over the past decade. The result is: the chef spends 99% of his time idly tapping pots and staring blankly in the kitchen, waiting for the waiter to bring the next onion.
This is the "Memory Wall." Over the past three decades, the speed of logic chips (computing power) has increased by nearly 100,000 times; however, the latency of DRAM (memory read/write speed) has improved by less than 10 times. The performance gap between the two has created an unbridgeable chasm.
Why Is Memory Progress So Slow? (The Limitations of Physics)
This is not due to a lack of effort from memory manufacturers, but rather differences in physical structure.
- Logic Chips: Rely on transistor miniaturization. The smaller the transistor, the faster its switching speed, leading to a natural surge in computing power.
- Memory (DRAM): Its essence is a collection of "tiny capacitors" that store electrical charges. If you make the "bucket" (capacitor) smaller, the "water" (charge) it can hold decreases, making it prone to leakage and discharge. To prevent data loss, engineers must spend more time "refilling the water (Refresh)." Therefore, miniaturization of memory can only increase its "capacity (higher density)" but makes it difficult to make it "run faster (lower latency)."
🌪️ Chapter Two: The Explosion of Generative AI — The Full Onset of the Computing Power Famine
If it were just for gaming or scrolling on smartphones, this Memory Wall would barely be tolerable. However, the birth of ChatGPT in late 2022 completely ignited this crisis.
Generative AI (Large Language Models, LLMs) possesses a terrifying characteristic: it is a "Memory-Bound" monster.
- Parameter Gluttony (Capacity Crisis): A GPT-4-level model boasts trillions of parameters. These parameter (weight) files are extremely large, often hundreds of GBs. You simply cannot fit them into the small cache (SRAM) inside the GPU; you can only store them in external memory (DRAM).
- Extreme Bandwidth Extortion (Bandwidth Crisis): When AI generates every single word of an article (such as this white paper), the GPU must "fetch and read all" of those hundreds of GBs of parameters from memory. If your "waiter" (bandwidth) isn't wide enough or fast enough, the GPU will be forced to wait endlessly.
- Data Movement Tax: This is the most fatal, yet least discussed, physical truth. In advanced AI servers, "the power consumed to move data from DRAM to the GPU is actually more than 100 times higher than the power consumed by the GPU to perform a single floating-point operation!" We spent immense effort developing 2nm technology and GAA, saving a minuscule amount of transistor power consumption; yet, in an instant, hundreds of watts of power are all wasted "on the journey of moving data." This is the brutal Data Movement Tax.
We are facing an unprecedented "computing power famine." Major manufacturers have purchased tens of thousands of H100 graphics cards, only to discover that the computing bottleneck is not in the processing power itself, but entirely tied to memory.
🚀 Chapter Three: Breaking the Wall — Memory's Full Counterattack
Sir, what do humans do when traditional flat roads become congested? The answer is: build elevated bridges, construct multi-level interchanges, or even move the kitchen directly into the warehouse.
To overcome this desperate Memory Wall, the memory industry, once considered a "boring standardized commodity (bulk material)," launched an epic architectural revolution. This has not only saved the development of AI but also fundamentally rewritten the semiconductor power landscape of Korea, the United States, and Taiwan.
In the upcoming Battle Zone Three, we will enter this battlefield dominated by data and bandwidth:
- 【3-1 HBM (High Bandwidth Memory) and SK Hynix's Counterattack】: Since flat data delivery is too slow, let's "stack memory vertically" like a skyscraper, then drill holes through it (TSV), and directly bind it next to the GPU! See how perennial runner-up SK Hynix used this move to knock memory giant Samsung off its pedestal.
- 【3-2 Warriors at the Edge (LPDDR5X/CAMM2)】: Servers can use expensive HBM, but what about phones and AI PCs without power outlets? See how next-generation planar memory undergoes extreme slimming and form transformation.
- 【3-3 The Data Skyscraper (3D NAND)】: This is a more exaggerated three-dimensional architectural feat than DRAM. See how humanity stacks storage flash memory like building the Taipei 101 tower, stacking 300 layers, and the magic of the "Controller chip" turning decay into wonder.
- 【3-4 The Ultimate Weapons to Break Architecture (CXL and PIM)】: If data delivery is too slow, why not just "let the warehouse learn to cook itself"? See how Processing-in-Memory (PIM) and CXL interconnect technology completely shatter the Von Neumann architecture.
- 【3-5 Taiwan's Path to Survival】: Under the dual pressure of the Korean giants and Micron, how do Taiwan's Winbond, Nanya Technology, and Powerchip Semiconductor Manufacturing Corporation avoid the main battlefield of the giants and find unique survival goldmines in "niche memory" and "foundry-hybrid" models?
Are you ready? Let's officially cross this Memory Wall and embrace the lifeblood of AI — HBM (High Bandwidth Memory).
In-depth Research · Quantitative Perspective
Want to gain more insights from semiconductor quantitative research?
【Insight Subscription Plan】Say Goodbye to Retail Investor Thinking: Build Your Alpha Trading System with "Quantitative Chips" and "Consensus Data"EDGE Semiconductor Research
📍 Series Map — Navigate the Complete EDGE Semiconductor Research →


