3-4 Breaking the Memory Wall —— CXL Interconnect Technology and PIM Processing-in-Memory
To overcome server capacity limits, CXL brings memory's 'USB moment' via PCIe for pooling & expansion, cutting cloud costs & sparking control chip demand. To end the 'data movement tax,' PIM integrates compute units into DRAM, enabling in-situ, no-movement computation. These shatter the Von Neuma...
After exploring the vertical stacks of HBM and the skyscrapers of 3D NAND, we have uncovered a critical hardware blind spot.
In the past three decades of computer development, if you felt your hard drive capacity was insufficient, you could simply buy an external hard drive and connect it via a USB cable for expansion. But what if you felt your "brain's memory (RAM)" wasn't enough? Unfortunately, you couldn't just plug in an external module. You had to shut down the computer, open the case, and precisely insert the memory into specific slots (DIMM Slots) on the motherboard, as close as possible to the CPU. This is because memory must maintain absolute synchronization and ultra-low latency with the CPU. The critical pain point: The number of slots next to the CPU on a server motherboard is fixed (usually 16 or 24). Once all slots are filled, the server's memory capacity is 'locked.' In today's world, where AI model parameters often reach trillions, this is essentially a death sentence for a server.
To break this physical limitation, giants like Intel, AMD, and ARM have jointly established a groundbreaking new standard. This will usher in an epic "USB moment" for the memory industry, allowing memory to be infinitely expandable by simply plugging it in, much like an external flash drive.
This technology is called CXL (Compute Express Link).
🔗 Chapter One: CXL — The Anywhere Door and Buffet Revolution for Memory
To enable external memory expansion, engineers focused on the most abundant channels on server motherboards, used for graphics cards and network cards: PCIe slots.
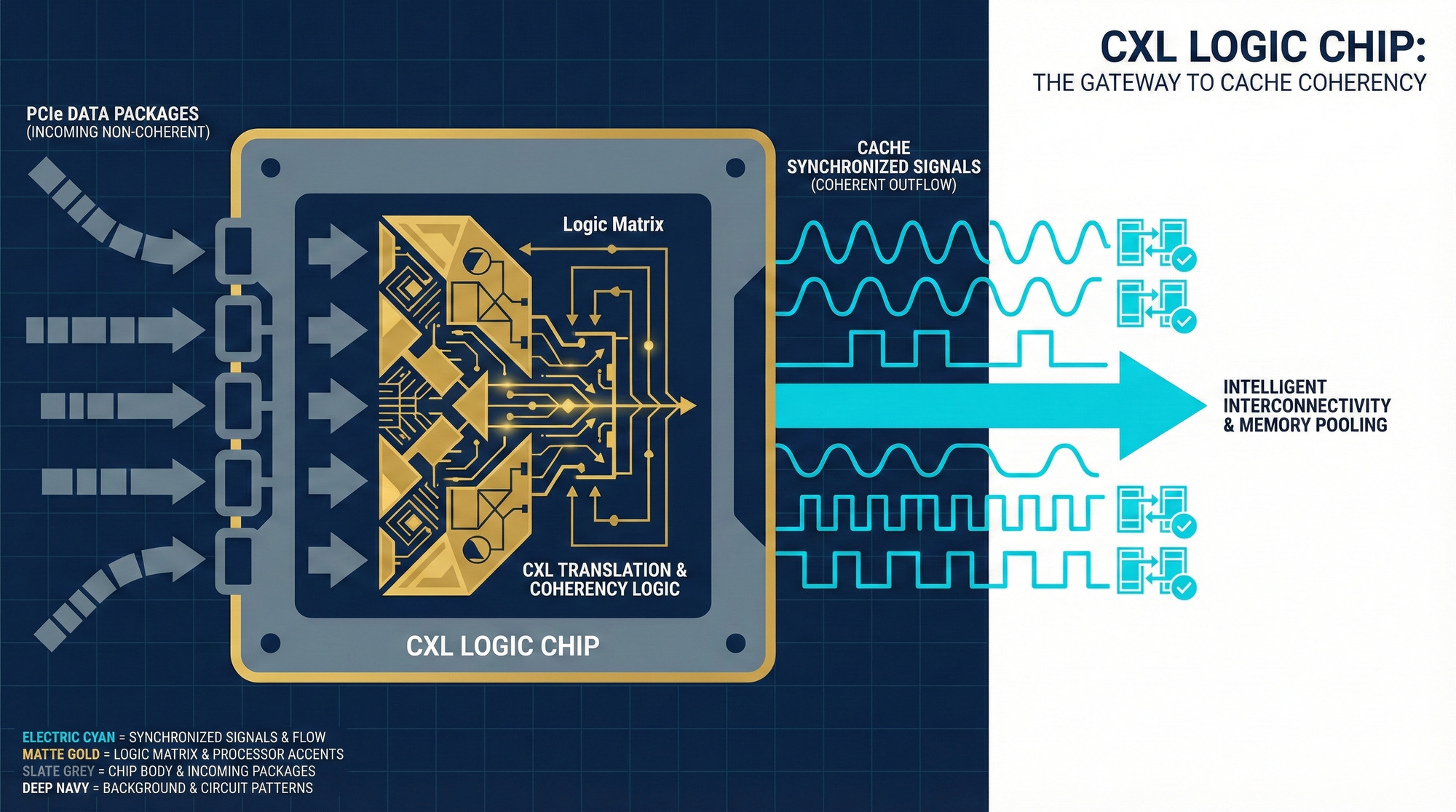
However, there's a significant technological gap here. While PCIe offers extremely fast transfer speeds, its underlying logic is merely for 'transporting packages (transferring files).' PCIe simply doesn't understand the highly stringent 'internal language' between the CPU and memory, which requires instantaneous synchronization.
This internal language, in computer science, is called 'Cache Coherency.' CXL's brilliance lies in leveraging PCIe's high-speed physical tracks, but running on them is a high-speed train that fully understands 'Cache Coherency.'
1. CXL's Three Modes (Type 1, 2, 3) and Infinite Expansion Cards
CXL defines three communication modes for different hardware devices. Among these, the one currently garnering the most attention from Wall Street and offering the largest business opportunities is Type 3 (Memory Expander).
Type 1 (Accelerator): Allows devices like SmartNICs, which do not have their own memory, to directly and without delay 'borrow' the CPU's memory.
Type 2 (GPU and other Compute Cards): Allows GPUs with their own HBM to simultaneously and seamlessly access DDR memory adjacent to the CPU, breaking down barriers between the two.
🌟 Type 3 (Memory Expander) — The Real Money Printer: This is an expansion card that looks like a graphics card, but it contains no GPU or compute chips, only dense DRAM memory modules. Purpose and Strategic Significance: What happens when all traditional DIMM slots on a server motherboard are full? No problem! Simply insert this CXL expansion card into a PCIe slot, and the server's memory capacity instantly soars by 512GB or even up to terabytes. This means that the memory capacity of AI servers has officially broken its physical shackles, achieving infinite expansion.
2. CXL 2.0 / 3.0's Killer Feature: Memory Pooling
If infinite expansion merely solves capacity issues, then the next revolution brought by CXL will directly save cloud giants like Google, Meta, and AWS tens of billions of dollars in hardware procurement costs.
This killer application is called 'memory pooling.'
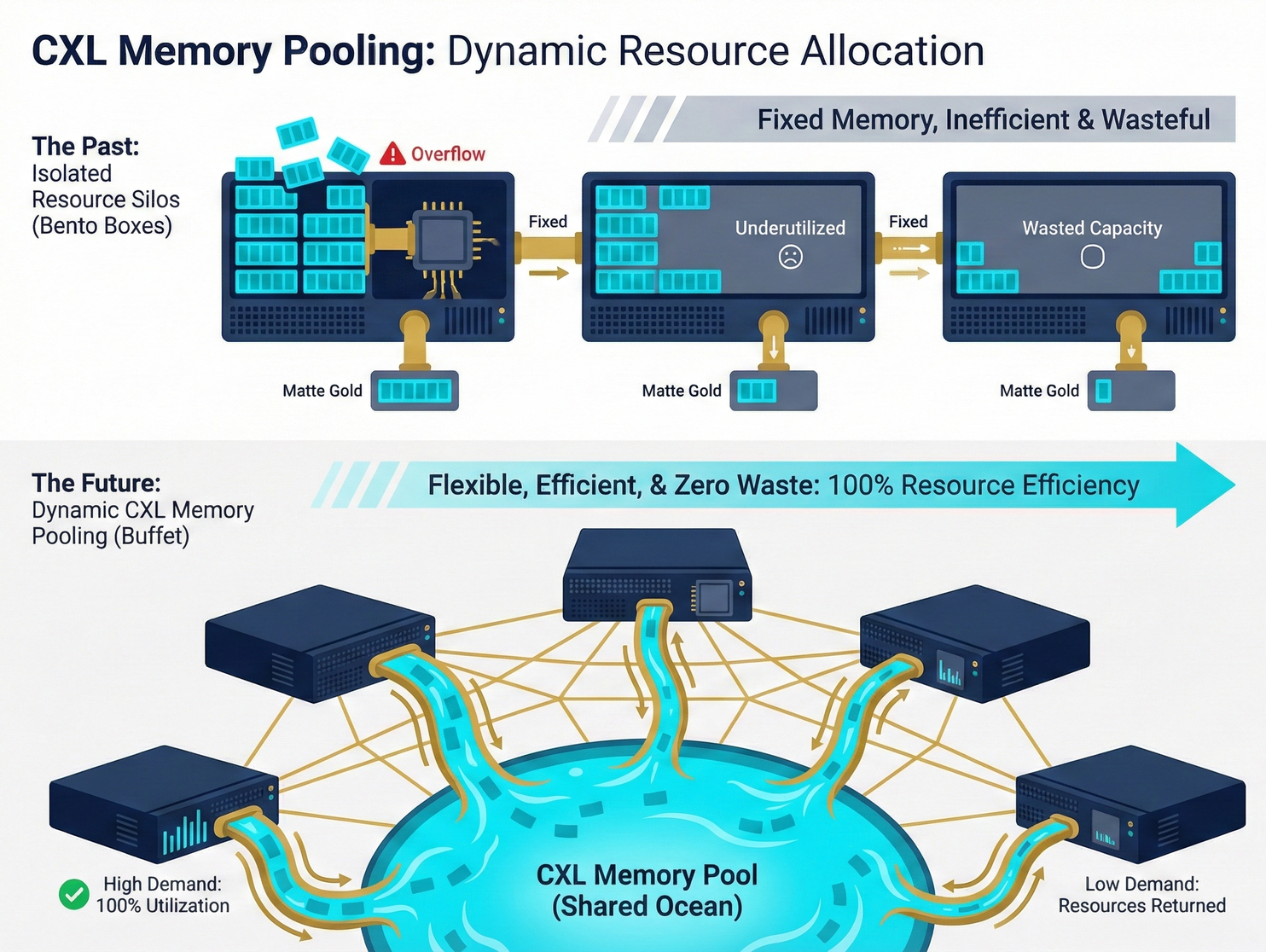
The Past Tragedy: Bento Box Model 🍱 Servers used to be isolated islands. Server A was allocated 64GB of memory, and Server B also had 64GB. If Server A suddenly needed to run a large AI model requiring 100GB, it would run out of memory and crash; meanwhile, Server B might only be performing simple web services, with 50GB of its 64GB sitting idle. Pain Point: Even if Server A starved for resources, it couldn't borrow the unused resources from Server B. This 'stranded memory' represented a significant waste in data center total cost.
The Current Revolution: Buffet Model 🍽️ CXL completely demolishes the walls between servers. Engineers can plug dozens, even hundreds, of CXL memory cards into an independent CXL Switch, forming an immense 'Memory Pool.' Operational Logic: Does Server A need 100GB? The system dynamically allocates 100GB to it instantly via CXL. Has Server A finished running its AI model? The system immediately reclaims that 100GB and reallocates it to Server C, which suddenly requires high capacity. Strategic Result: Hardware utilization instantly soars from a previous 40% to over 80%. CSPs (Cloud Service Providers) no longer need to blindly purchase expensive memory for every server, leading to a dramatic, cliff-like reduction in procurement costs.
🤑 Chapter Two: The Arms Dealers — Who is Getting Rich in the CXL Blue Ocean?
Sir, CXL is not a near-monopoly like HBM, dominated almost exclusively by SK Hynix and TSMC. CXL represents a fundamental overhaul of the entire server architecture, fostering a vast and highly profitable new ecosystem.
1. CXL Controller (Controller Chip): The Fattest Chokepoint
As mentioned earlier, when memory is plugged into a PCIe card, the CPU doesn't inherently recognize it. There must be an extremely intelligent 'translation chip (Controller)' in between, responsible for real-time translation of PCIe signals into the memory's cache language.
Astera Labs (ALAB.US): This is an absolute leader currently favored on Wall Street. Its Leo series CXL memory controller chips represent the current global market leader with the most mature technology. Thanks to its dominant position in AI server interconnects, its stock price experienced an epic surge after its IPO.
Montage Technology (Montage, China A-shares): Although based in China, Montage possesses world-leading capabilities in memory interface chips (RCD/DB). Its deep CXL strategic positioning makes it a giant not to be overlooked.
Microchip / Rambus: These traditional leaders in chip interconnects and high-speed interfaces are also actively vying for a share of this translation chip market.
2. Server Architecture and Remote Management (BMC)
The introduction of CXL means that server motherboard designs must be completely redrawn.
Wiwynn (6669.TW): As a key development partner for Meta and Microsoft, when major clients demand 'memory pooling' to save costs, Wiwynn must be at the forefront of designing next-generation AI server racks that support CXL switches and high-density PCIe slots. Wiwynn is leading the way in CXL system architecture.
Aspeed (5274.TW): This company is Taiwan's stock king and the undisputed global leader in Baseboard Management Controller (BMC) chips. When data centers transition from a 'bento box model' to a 'buffet model,' hardware resource management becomes extremely complex (who borrowed memory? who returned it? is there overheating?). This necessitates more powerful, higher-end BMC chips for cross-server resource monitoring. The advent of the CXL era has directly boosted Aspeed's chip shipments and average selling price (ASP).
🧠 Chapter Three: PIM (Processing-In-Memory) — No Moving, Direct Computing!
Sir, in the previous Section 3-0, we discussed the 'compute famine' and the alarming 'Data Movement Tax.'
Current computer processing models are still tightly bound by the 70-year-old 'Von Neumann architecture': 'Moving data from storage and transporting it long distances to the kitchen (CPU/GPU) for processing.'
No matter how wide you pave the roads with HBM, or how large you build the warehouses with CXL, you ultimately still have to 'move' the data.
Do you know where all the power consumed by AI servers goes during operation?
The harsh physical truth is: The process of moving data consumes as much as 60% to 90% of the entire system's power. The power actually used for computation, by contrast, is pitifully small.
Faced with this absurd waste, memory engineers proposed a logic that is almost heretical yet incredibly elegant: 'Since moving data is so power-intensive, let's stop moving it! Let's process the data directly in the warehouse (Memory)!'
This is the ultimate holy grail of semiconductor architecture: PIM (Processing-In-Memory).
1. Memory Can Compute Too: Placing Tiny Chefs in the Warehouse
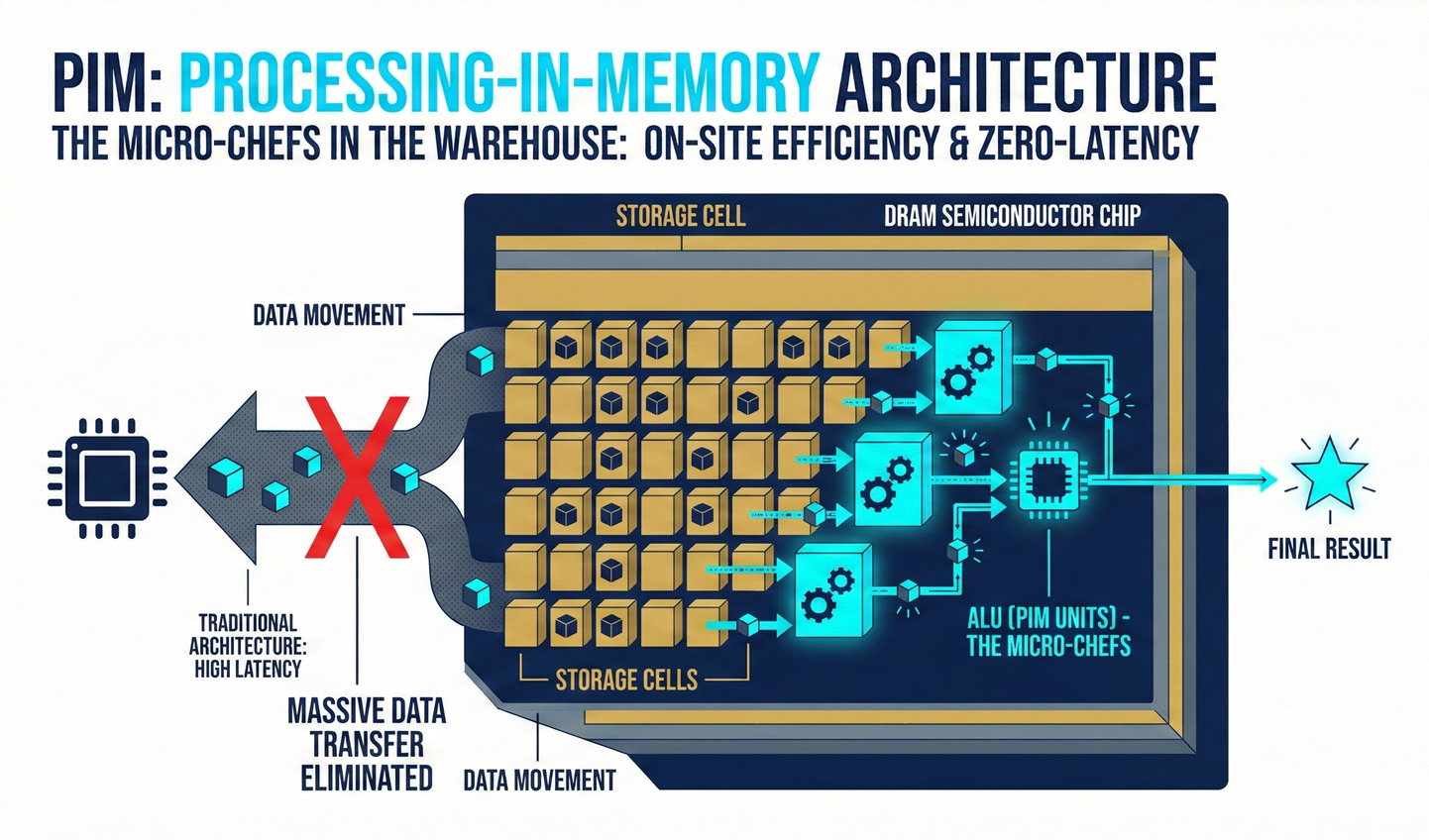
Method: Traditional DRAM chips only contain cells, each with a capacitor for storing data. Under the PIM architecture, engineers directly integrate thousands of simple micro-arithmetic logic units (ALUs) within the DRAM chip itself.
Physical Capabilities: Unlike CPUs, these ALUs are not intelligent enough to perform complex logic; they can only execute the most basic 'addition' and 'multiplication' operations.
A Perfect Match for the AI Era: Coincidentally, the inference process in AI deep learning fundamentally involves hundreds of billions of matrix multiplications and additions (MACs).
Absolute Advantages: Extreme Power Saving and Zero Latency. Data doesn't even need to leave the memory! When computation is required, the adjacent tiny 'chefs' process it on the spot, sending only the 'final result' back to the CPU. This completely eliminates the immense power consumption and time delays associated with data movement.
2. Current Status: The Show of Force from HBM-PIM and AiM
This is not science fiction; the Korean giants have already delivered physical chips.
Show of Force: Samsung has demonstrated HBM with PIM functionality (HBM-PIM); SK Hynix has also launched GDDR6 chips named AiM (Accelerator in Memory).
Killer Applications: Voice recognition, recommendation systems (e.g., TikTok or Netflix feeds). These AI tasks are characterized by extremely simple computational logic but require sifting through 'massive' amounts of data. This is simply the perfect stage for PIM to shine.
3. PIM's Ultimate Bottleneck: The Growing Pains of the Software Ecosystem
If PIM is so revolutionary, why isn't it widespread yet?
Because with this technology, 'hardware is advancing too rapidly for software to keep up.'
Programmers worldwide have spent decades growing up with the logic of 'CPU / GPU computing' (e.g., NVIDIA's CUDA ecosystem). Now, asking them to rewrite underlying code to call upon 'memory' to assist with computations overturns all established programming habits and compiler designs.
The widespread adoption of PIM requires a software revolution similar to NVIDIA's introduction of CUDA. This will take time, but it is undoubtedly the ultimate solution for breaking the memory wall.
📊 3-4 Strategic Summary: The Future Landscape and Power Map of Battlefield Three (Memory)
This is a prolonged and magnificent memory revolution. We've journeyed from the skyscrapers of HBM to CAMM2 for edge computing, then delved into the deep wells of 3D NAND, and finally, in CXL and PIM, we've seen the dawn of breaking traditional architectures. This strategic summary table condenses all the tools at our disposal and their roles as organs in the AI era:
This post is for subscribers only
Sign up now to read the post and get access to the full library of posts for subscribers only.