Table of Contents
- Executive Summary: The Next Capex Cycle
- Infrastructure Deep Dive: Anatomy of NVIDIA's Vera Rubin Architecture
- Software Defined Physics: The Paradigm Shift from Language to Reasoning
- The Great Debate: Simulation (NVIDIA) vs. Real-World Testing (Tesla)
- Macro Constraints: Energy, Singularity & Geopolitics
- Investment Thesis: Winners, Losers, and Watchlist
1. Executive Summary
1.1 The Signal: The End of the Digital Age of Discovery, The Dawn of the Industrial Revolution
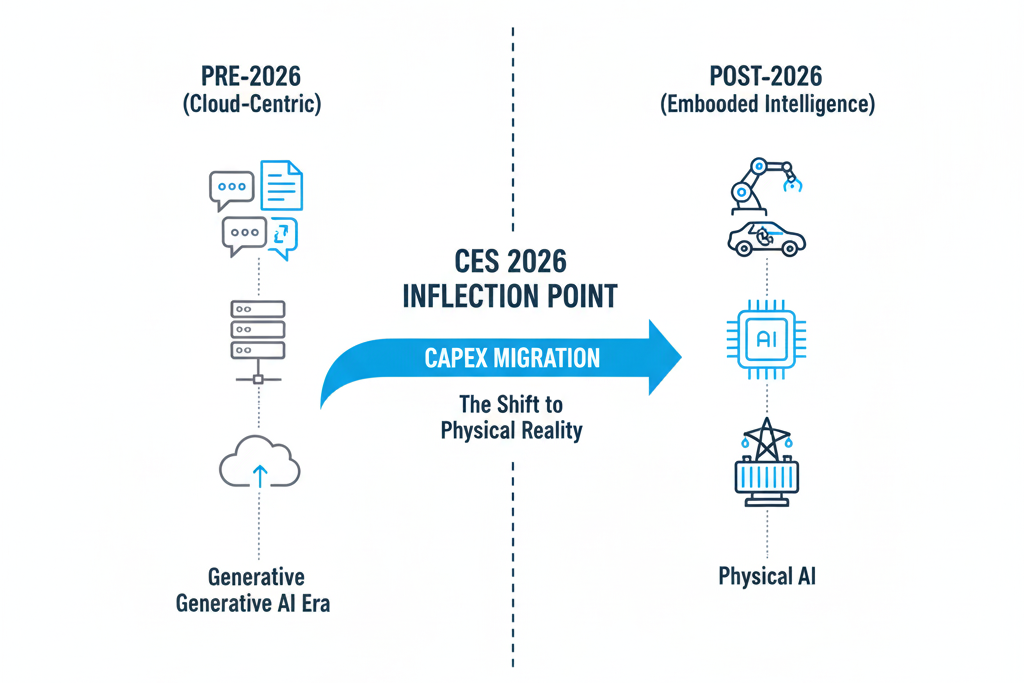
CES 2026 sent a clear and resounding signal: the development cycle of artificial intelligence has officially crossed a "Watershed Moment."
Over the past three years (2023-2025), the market's main theme was **Generative AI**, with its outputs being "Pixels" and "Tokens." However, with NVIDIA's introduction of the Vera Rubin architecture and Tesla's demonstration of Optimus's mass production progress, 2026 marks the inaugural year of the **Physical AI** era.
The battlefield for AI has extended from "cloud servers" to the "physical world." It's no longer just about how beautifully a Chatbot can write poetry, but about whether AI can understand gravity, friction, and causality to control robots and autonomous vehicles to perform concrete labor.
1.2 The Shift: The Paradigm Shift in Capital Expenditure (CapEx)
For investors, changes in technical terminology signify a restructuring of capital flows. We observe the following structural shifts in CapEx priorities:
- Diminishing Returns in Training: Simply stacking computing power to train larger Large Language Models (LLMs) is seeing declining marginal utility.
- Rise of Simulation & Inference: New growth areas lie in **Physics Simulation** — teaching AI to understand physical laws, and **Edge Inference** — enabling end devices with real-time decision-making capabilities.
- Hardware-Defined Software: The software Model Layer is facing the risk of **Commodification**, with value being squeezed towards both ends: upstream to **Energy and Advanced Packaging**, and downstream to **Embodied Devices**.
1.3 Investor Takeaway: One-Page Mental Model
To help institutional investors navigate technical noise, we have established the following investment mental framework:
The Core Thesis: The source of Alpha (excess returns) in 2026 will no longer be "who owns the largest model," but "who owns the most accurate interpretation of the physical world."
1.4 Key Risks
- The Energy Wall: As Physical AI's demand for inference compute power rises exponentially, power infrastructure (transformers, grid capacity) will replace chips as the biggest supply bottleneck.
- Sim-to-Real Gap: If NVIDIA's simulation environment cannot perfectly map the chaos of the real physical world, the value of its ecosystem will face re-evaluation.
Chapter Two: Infrastructure Deep Dive — Anatomy of NVIDIA's Vera Rubin Architecture
Infrastructure Deep Dive: The Engine of Physical Reality
Analyst Note:
The introduction of the Vera Rubin architecture (R-Series) marks a complete shift in NVIDIA's strategic focus. If Hopper and Blackwell were designed to enable humans and machines to "converse" (Generative AI), then Rubin is designed to enable machines to "act" in the physical world (Physical AI). This chapter will deeply deconstruct how Rubin addresses the computational power and memory bottlenecks in physical simulation through HBM4, CoWoS-L advanced packaging, and a brand-new Unified Memory architecture.
2.1 Defining the Bottleneck: Why Blackwell Can't Run Physical AI? (The Physics Gap)
Before delving into Rubin's technical details, we must first understand the limitations the existing Blackwell (B200) architecture encounters when facing Physical AI. This is not simply a matter of insufficient computational power (FLOPS), but a fundamental architectural mismatch.
Blackwell's design was initially to optimize matrix multiplication operations for LLMs (Large Language Models). However, Physical AI processes **4D data (3D space + 1D time)**, shifting its computational nature from "statistical probability" to "Partial Differential Equations (PDEs)." When we try to use chips designed for training Chatbots to simulate fluid dynamics or robot kinematics, we encounter a "Dimensionality Explosion."
For example, simulating a simple physical scene: **"A robot finger pressing a liquid-filled balloon for 1 second."** This sounds simple, but for a chip, it means simultaneously calculating the following variables:
- Real-time changes in fluid dynamics (Navier-Stokes equations)
- Non-linear deformation of soft materials (FEM)
- Light refraction (Ray Tracing) and surface tension
The state parameters and memory bandwidth consumed for this short 1-second simulation are on the order of an LLM processing billions of Tokens. In such high-sparsity computations, GPUs cannot perform efficient batch processing as they do for text.
This leads to the most severe efficiency problem currently: **The Memory Wall**. When running high-precision simulations on the Blackwell architecture, we observe extremely poor resource allocation:
- Low Compute Utilization: Expensive Tensor Cores are often idle for over 60% of the time.
- Bandwidth Bottleneck: The chip isn't calculating slowly; rather, the data movement speed cannot keep up with the computation speed. This results in customers paying an expensive TCO (Total Cost of Ownership) but only getting half the performance.
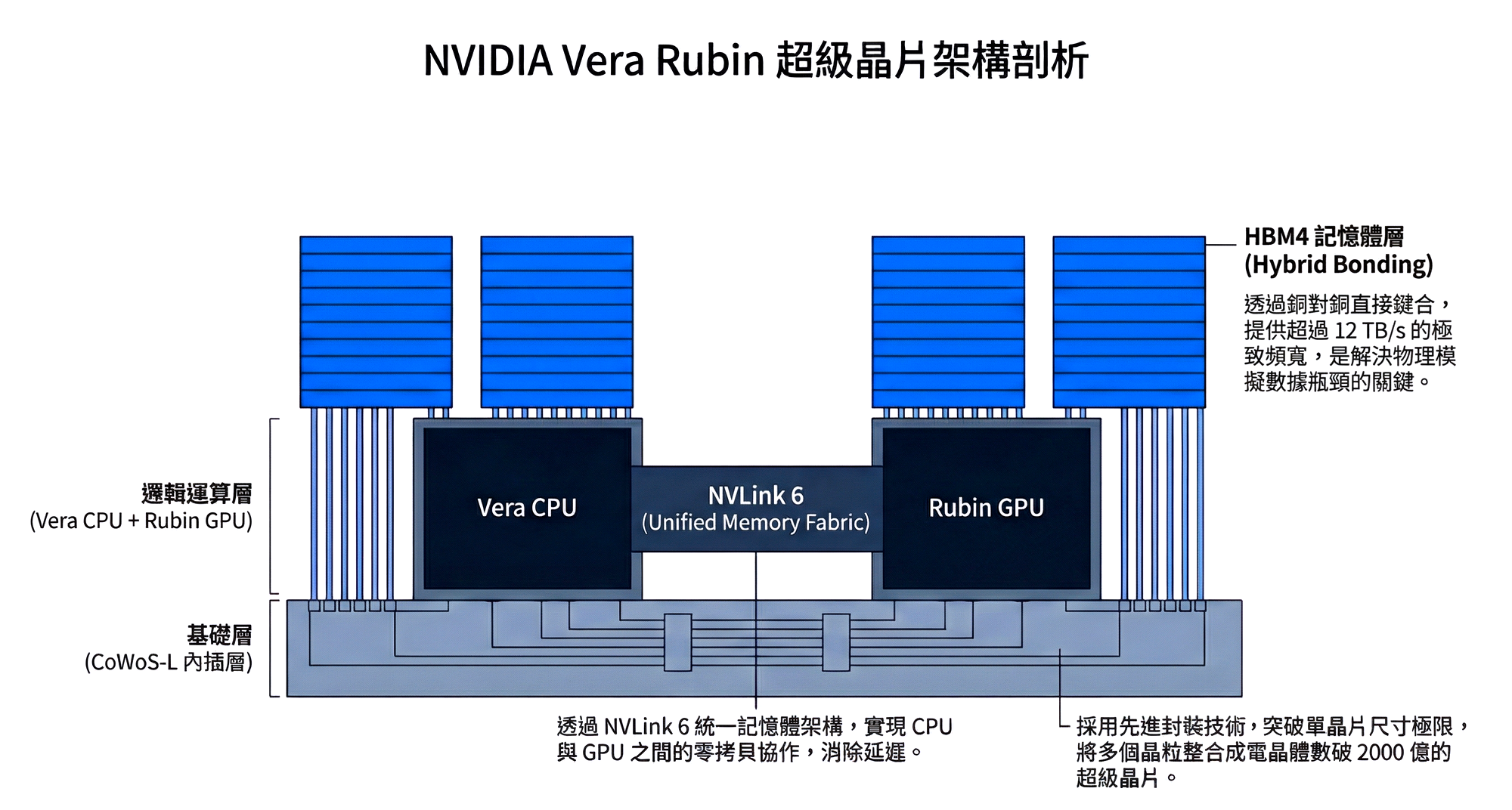
2.2 Vera Rubin Architecture Deep Dive: Chip-Level Reconstruction (Architecture Anatomy)
To break the aforementioned physical bottlenecks, NVIDIA's Vera Rubin platform, launched in 2026, is not a linear upgrade of the B200, but a radical reconstruction based on the philosophy of "Data Center as a Computer." This generation's architecture has been optimized for physical computing across process technology, memory, and packaging.
2.2.1 Process Technology and Packaging: The Battle to Extend Moore's Law
The Rubin GPU (R100) is expected to utilize **TSMC N3P (3nm Performance)**, even tentatively introducing **N2 (2nm GAAFET)** technology. The Gate-All-Around (GAA) transistor structure offers better current control and lower leakage, which is crucial for Rubin with its hundreds of billions of transistors; otherwise, its power consumption would easily exceed physical heat dissipation limits.
However, process miniaturization alone is no longer sufficient to sustain performance doubling. Rubin has encountered the physical ceiling of chip manufacturing — the **Reticle Limit**, meaning the size of a single chip cannot be further increased. Therefore, NVIDIA has adopted the extremely aggressive **CoWoS-L (Chip-on-Wafer-on-Substrate with Local Si Interconnect)** packaging technology.
This design offers two key advantages:
- Breaks Size Limits: The R100 is no longer a single die, but a "superchip" composed of multiple Compute Dies and IO Dies stitched together. The number of transistors within a single package is expected to exceed **200 billion**.
- LSI Local Interconnect: Through Silicon Bridge technology, communication speed between different chiplets approaches intra-chip speeds, ensuring that overall performance is not compromised in a multi-die architecture.
2.2.2 Memory Revolution: HBM4 and Hybrid Bonding
If CoWoS is the skeleton, then **HBM4 (High Bandwidth Memory Gen 4)** is Rubin's bloodstream. This is also the most critical key to solving the aforementioned "physical simulation bottleneck."
The HBM4 first introduced in Rubin is not just a bandwidth upgrade; it's a revolution in stacking technology. NVIDIA has introduced **Hybrid Bonding** technology, a process that achieves atomic-level connections directly via copper-to-copper, replacing traditional micro-bumps. This allows memory to "grow" directly on top of logic chips (Logic-on-Logic 3D Stacking).
The leap in specifications brought by this technology is astonishing:
- Extreme Bandwidth: Expected to exceed **12 TB/s** (a 50% increase compared to B200's 8 TB/s), completely clearing the data pipelines for physical simulation.
- Ultra-Large Capacity: Utilizing **16-Hi (16-layer stack)** technology, the memory capacity per GPU is pushed beyond **288GB**. This means massive world model parameters can be loaded at once, eliminating repeated reads and writes between storage and memory.
- Low Latency and Low Power Consumption: Shortens the physical distance of data transmission, significantly reducing power consumption per bit (pJ/bit), which is crucial for robotics computing requiring high-frequency, real-time responses.
2.2.3 Vera CPU: The Last Piece of the Unified Memory Puzzle
In the Rubin platform, the role of the new generation Arm-based CPU, codenamed "Vera," has undergone a qualitative transformation. In traditional architectures, the CPU often acts merely as the "landlord" issuing commands, while the GPU is the "tenant" doing the heavy lifting. Their memories are independent, and data movement is full of latency.
Rubin achieves a true **Superchip** architecture through **NVLink 6**. The Vera CPU and Rubin GPU now share the same Unified Memory Space. This holds immense strategic significance in Physical AI application scenarios:
- Zero-Copy Collaboration: The robot's operating system (ROS) runs on the CPU, while vision processing and physics computations run on the GPU.
- Eliminates Latency Variables: The CPU can directly read GPU memory data, and vice versa. This directly eliminates communication latency previously caused by insufficient PCIe bandwidth, ensuring robots can react in milliseconds to unforeseen situations.
2.3 Evolution of Compute Units: Tensor Core Born for Physics (The Physics Solver)
In the era of Physical AI, the definition of the GPU's role is undergoing a quiet yet dramatic revolution. Previously, GPUs were seen as accelerators for graphics rendering or text generation; however, under the Rubin architecture, they must evolve into high-precision "Physics Solvers." This is not just about stacking computational power, but a targeted improvement of the underlying logic of the Streaming Multiprocessors.
The Blackwell architecture introduced FP4 (4-bit floating point) to extremely accelerate LLM inference efficiency, which is perfect for language models with higher fault tolerance. However, the physical world is unforgiving and intolerant of ambiguity. When simulating fluid dynamics, material stress, or robot kinematics, the distribution of precision requirements is extremely polarized: on one hand, we need very high-precision mathematical operations to solve Partial Differential Equations (PDEs) to ensure the "Ground Truth" of the simulation; on the other hand, robots making decisions at the edge require extremely low latency and low power consumption.
To address this dual demand, Rubin's **third-generation Transformer Engine** demonstrates unprecedented "dynamic spectrum" adaptation capabilities.
- Mixed-Precision Physics: Rubin no longer treats all data equally, but introduces "Adaptive Sparsity" technology. It intelligently identifies key regions in a simulated scene. For example, when simulating water flow impacting a rock, the system automatically uses high-precision **FP64 (double-precision)** for calculations at the fluid edges of the contact surface, while downgrading to FP8 for static objects in the background. This dynamic adjustment is expected to increase the overall efficiency of physical simulation by **4-6 times** with virtually no sacrifice in simulation fidelity.
- Hardware-Accelerated PINNs (Physics-Informed Neural Networks): This is one of the most forward-looking designs in the Rubin architecture. Traditional scientific computing relies on formulas, while AI relies on data. PINNs, on the other hand, embed physical laws (such as conservation of energy, conservation of momentum) directly into the neural network's loss function. Market intelligence indicates that Rubin's Tensor Cores have added specific instruction sets dedicated to accelerating **gradient computation** and **boundary condition solving**, which are common in PINNs. This means NVIDIA is attempting to fully integrate "scientific computing" and "AI inference" at the hardware level.
2.4 Interconnect Architecture: The Rack-Scale Architecture
When we shift our focus from individual chips to the entire data center, the challenges become even more formidable. In Physical AI training, model parameter scales will move from Trillions to Quadrillions. At this magnitude, no single GPU, however powerful, will suffice; the key to victory lies in "Communication."
In physical simulation, causality means that one action affects everything. A "left-hand movement" computed by GPU A might instantaneously affect the "water flow changes" computed by GPU B. This "All-to-All" communication demand imposes nearly stringent requirements on bandwidth and latency. The Rubin architecture, through sixth-generation NVLink, attempts to redefine the internal topology of the rack.
Rubin's core concept is "Switchless Topology," or more precisely, the internalization of switching functions.
- NVLink 6 Bandwidth Leap: The new generation of NVLink is expected to provide an astonishing throughput of up to **1.8 TB/s (unidirectional)** / **3.6 TB/s (bidirectional)**. This makes data exchange speeds between multiple GPUs almost equivalent to internal chip access speeds.
- The Last Mile of Copper: Although Silicon Photonics is seen as the future for long-distance transmission, within a single rack (Intra-Rack), Rubin still adheres to using **Copper Backplanes**. This is a pragmatic choice based on physical limits: for short-distance transmission, copper cables offer lower latency and power consumption than optical fibers. The Rubin rack design will extend the concept of the GB200 NVL72, connecting 72 or even 144 GPUs directly via copper cables to operate as one massive "superchip," completely eliminating latency losses from traditional optical-electrical-optical (O-E-O) conversions.
2.5 Thermal Management and Infrastructure Standards (Liquid Cooling Standard)
With the extreme compression of transistor density and the stacking of HBM4, Rubin's Power Density will reach unprecedented levels. This is not only a challenge for chip design but also a declaration of war on the physical infrastructure of data centers.
In the Rubin generation, **Air Cooling** has officially become a thing of the past. For data centers deploying Rubin clusters, **Direct-to-Chip Liquid Cooling (DLC)** is no longer a premium option but a mandatory standard.
- Breakthrough in Thermal Design Power (TDP): The TDP of a single Rubin GPU is expected to exceed **1,200W**, possibly even higher. Traditional fan-based cooling will be completely ineffective at such heat flux.
- Infrastructure Retrofitting: This will lead to a shake-up in the data center industry. Existing air-cooled data halls will be unable to support Rubin deployments, forcing everyone from colocation providers to Hyperscalers to undertake expensive infrastructure upgrades. This also explains why thermal management companies like Vertiv (VRT) have received high valuations in the capital markets, correlated with chip stocks — because in the Rubin era, "**cooling capacity is the compute limit**."
2.5 The Economics of Simulation: Shorting Real-World Testing Costs
The ultimate test of technology is always economic benefit. The core question investors most frequently ask is: why are companies willing to continue investing hundreds of millions of dollars in Rubin clusters at a time when CapEx is already soaring? The answer lies in a new valuation metric: **Cost per Simulated Hour**.
In the R&D of Physical AI, data acquisition costs exhibit extreme nonlinearity. Training robots in the real world is an extremely expensive and inefficient process. Imagine teaching a humanoid robot "how to carry a glass on a slippery surface without falling." In the physical world, this means thousands of falls, damage to expensive parts, lengthy repair cycles, and potential injury risks to personnel. For extreme scenarios like disaster relief or nuclear power plant maintenance, the cost of acquiring real data is even infinite (because we cannot intentionally create disasters just to collect data).
The value proposition of the Rubin architecture lies in its digital compression of these high marginal costs. Through the immense bandwidth provided by HBM4 and the zero-copy architecture of Unified Memory, Rubin can parallel-simulate millions of robot instances in Omniverse at a cost less than one ten-thousandth of real-world costs.
- Substitution Effect: Rubin is effectively "shorting" real-world testing costs. When enterprises discover that the cost of purchasing a Rubin DGX rack is far lower than the operational expenditure (OpEx) of building a real-world test fleet or robotics lab, hardware procurement transforms from a "cost center" into an "efficiency tool."
- Unit Economics: If Rubin can reduce the cost for a robot to acquire a skill from **$10,000/skill** in the real world to **$0.01/skill** in the virtual world, then it creates a massive deflationary effect, which is the prerequisite for Mass Adoption.
2.6 Full-Stack Lock-in: The Ultimate Vendor Lock-in at the Physical Layer
If CUDA was NVIDIA's moat for the past decade, the Rubin architecture is digging a deeper, more formidable trench — the "**right to define physics**."
In the LLM era, migrating models from NVIDIA to AMD or Intel GPUs, while painful, was not impossible (mainly involving code translation). However, in the Physical AI era, such migration will face the risk of "Brain Rejection." A robot's neural network "grows up" under the physical laws simulated by Rubin chips; it relies on specific floating-point precision, specific ray tracing behavior, and specific fluid dynamics solvers.
Because different hardware architectures have subtle differences in how they solve physical equations at the microscopic level, porting a robot model trained on Rubin to a competitor's chip could lead to tiny deviations in the robot's movements in the real world. For generating text, this might just mean a different word choice; but for controlling a robot, it could mean falling or crashing.
Therefore, the Rubin architecture creates a **Full-Stack Lock-in**:
- Hardware Layer: Requires NVLink interconnects and Spectrum-X switches to ensure low-latency communication.
- Software Layer: Requires Isaac Sim and PhysX engines to ensure physical consistency.
- Result: Once a customer chooses NVIDIA's ecosystem to train robots, they are virtually unable to leave. NVIDIA is extending its influence from the "compute layer" down to the "physical truth layer."
2.7 Strategic Risk: Compute Centralization and Market Structure Deformation (Risk of Centralization)
The launch of the Rubin architecture also signals a dramatic deformation of the AI compute market structure. As "Data Center as a Computer" becomes the standard, the sales threshold for a single compute unit is raised to "Rack-Scale," with unit prices easily reaching millions of dollars.
- Entry Barrier Inflation: This will lead to further concentration of compute resources towards the "Magnificent 7" (the seven largest US tech companies) and national sovereign AI funds. Small and medium-sized enterprises, academic institutions, and startups will be unable to build their own infrastructure, instead having to rely on APIs provided by giants or lease compute power.
- The Missing Middle: While this benefits NVIDIA in the short term by locking in high-value customers, in the long run, a lack of active "middle-class developers" could weaken the ecosystem's innovation diversity. If Physical AI R&D power becomes highly concentrated, the industry might face "too big to fail" systemic risks.
Chapter Three: Software Defined Physics — The Paradigm Shift from "Language" to "Reasoning"
Software Defined Physics: The Pivot from Language to Reasoning
If the Rubin architecture is designed to give AI a robust body, then this chapter explores how AI develops a "cerebellum" and "prefrontal cortex" at the software level. In 2026, the focus of software competition has shifted from "who can write better poetry (LLM)" to "who can more accurately predict physical consequences (Physical AI)." This paradigm shift will redefine the software value chain.
3.1 Tokenization of Physics: Giving AI the Dimensions to Understand the World (Tokenization of Physics)
For artificial intelligence to understand a real world full of friction, gravity, and fluid dynamics, the first immense mathematical challenge is "translation." Physical quantities in the real world are **continuous**, while the computational logic of digital computers is **discrete**. The success of LLMs in recent years stemmed from our ability to segment discrete text into "Tokens." Now, NVIDIA and leading research institutions are undertaking an even more formidable engineering task — "**Tokenization of Physics**."
This is not merely a technical fine-tuning but a qualitative change in underlying logic. Past Generative AI operated based on **Correlation** — it observed many pixel arrangements of "tilting cups" often accompanied by "liquid spilling," and thus imitated and generated similar visuals, but it didn't understand "why."
The new generation of **LWM (Large World Model)**, however, attempts to vectorize physical attributes. When an AI camera captures a glass, it no longer reads just an RGB pixel matrix, but a set of high-dimensional vectors containing Implicit Physical Properties:
- Mass Estimation
- Friction Coefficient
- Material Stiffness/Compliance
This shift means AI's cognitive abilities have evolved from "imitation" to "Causal Inference." AI no longer just draws what spilled water looks like; instead, it calculates when and how far liquid will spill based on gravitational acceleration $g$ and fluid viscosity coefficient $\mu$. This mastery of causality is an absolute prerequisite for Physical AI to move beyond screens and into factories and homes to perform hazardous tasks.
3.2 Platform Ambition: Building the Android of Robotics (Project GR00T & Cosmos)
After solving the challenge of "understanding physics," the next business problem is: how to address Fragmentation? The current robotics industry is like the mobile phone market before 2007, where every hardware manufacturer had to write their own operating system and train their own motion control algorithms, leading to extremely low efficiency.
Jensen Huang's answer is an ambitious platform strategy, aiming to become the "greatest common divisor" of the robotics industry:
- Project GR00T (Generalist Robot 00 Technology): This is the foundation model for robots. NVIDIA's strategy is to provide a "pre-trained brain" that has already learned universal skills like balancing, navigation, and grasping. This is similar to the Android operating system, where developers don't need to teach robots how to walk from scratch, but can focus on developing higher-level applications (e.g., brewing coffee, moving tires).
- NVIDIA Cosmos: If GR00T is the brain, Cosmos is the "matrix" for training that brain. This is a deeply integrated World Model with a physics engine. It allows developers to conduct large-scale Reinforcement Learning in digital twin environments for specific physical scenarios (e.g., slippery wet roads).
Investment Perspective:
This "software-defined standard" strategy aims to create extremely high Switching Costs. When all robot developers become accustomed to calling GR00T's APIs within the Isaac Sim environment, NVIDIA successfully extends its moat from hardware to the developer ecosystem.
3.3 Decentralization of Reasoning: When Edge Devices Begin to "Think Slowly" (Reasoning at the Edge)
One of the most disruptive technological highlights at CES 2026 was the decentralization of **Reasoning** capabilities from the cloud to the edge. Past autonomous driving or robot control largely belonged to "System 1" (Fast Thinking) in psychology, meaning intuitive reflexes based on pattern recognition – stopping at a red light. However, driven by new-generation automotive chips like **Alpamayo**, edge devices have begun to acquire "System 2" (Slow Thinking) capabilities.
This is a new paradigm based on **Inference-Time Compute**. Imagine a complex scenario: a truck is parked on the roadside with its hazard lights on, and there's oncoming traffic.
- Traditional AI (System 1): Due to conflicting rules (do not cross the lane line vs. obstacle ahead), it might brake abruptly, causing traffic congestion behind.
- Physical AI (System 2): Performs **Chain-of-Thought** reasoning:
- Observes truck status (unoccupied, hazard lights) → Infers: it will not move temporarily.
- Calculates oncoming vehicle speed and distance → Infers: I have a 3.5-second window.
- Decides: Accelerate and cross the lane line to overtake within 0.5 seconds.
This deep reasoning, performed in real-time at the edge, fundamentally changes the demand landscape of the hardware supply chain:
- Sensor Upgrades: 2D images from cameras are insufficient to provide precise physical reasoning data. **4D Imaging Radar** and **Solid-state LiDAR** will become standard, as only they can provide accurate depth and velocity vectors.
- Software Architecture Reconstruction: The stability requirements for **Real-Time Operating Systems (RTOS)** have escalated from "not crashing" to "zero latency." This will drive demand for licenses for systems like BlackBerry QNX or specific Linux embedded versions.

3.4 Potential Shadows: Hallucinations and the Challenge of Open Source (Failure Modes)
This software-defined path is not without its challenges; investors need to pay attention to two major risks:
- World Model Hallucination: While simulators are becoming increasingly realistic, physics engines often suffer from "over-smoothing" issues. For example, a simulated environment might overlook tiny oil stains or uneven surfaces present on real ground. Such details, "averaged out" in simulation, are often the culprits causing robots to slip in the real world. If the Sim-to-Real gap cannot be bridged by real-world data, NVIDIA's simulation path will face scrutiny.
- The Open Source Threat: The market structure is not static. Open-source VLA (Vision-Language-Action) models emerging on Hugging Face are rapidly catching up. If Meta or Google decide to open-source a powerful general-purpose robot model (similar to Llama's role in the LLM domain), NVIDIA's pricing power at the software layer would instantly crumble. This also explains why NVIDIA is so eagerly pushing the Rubin architecture — only through extreme hardware-software binding can it defend its high-margin moat in a future where software might trend towards Commodification.
Chapter Four: The Great Debate — Simulation vs. Real-World
The Battle for Truth: The Matrix vs. Martial Arts
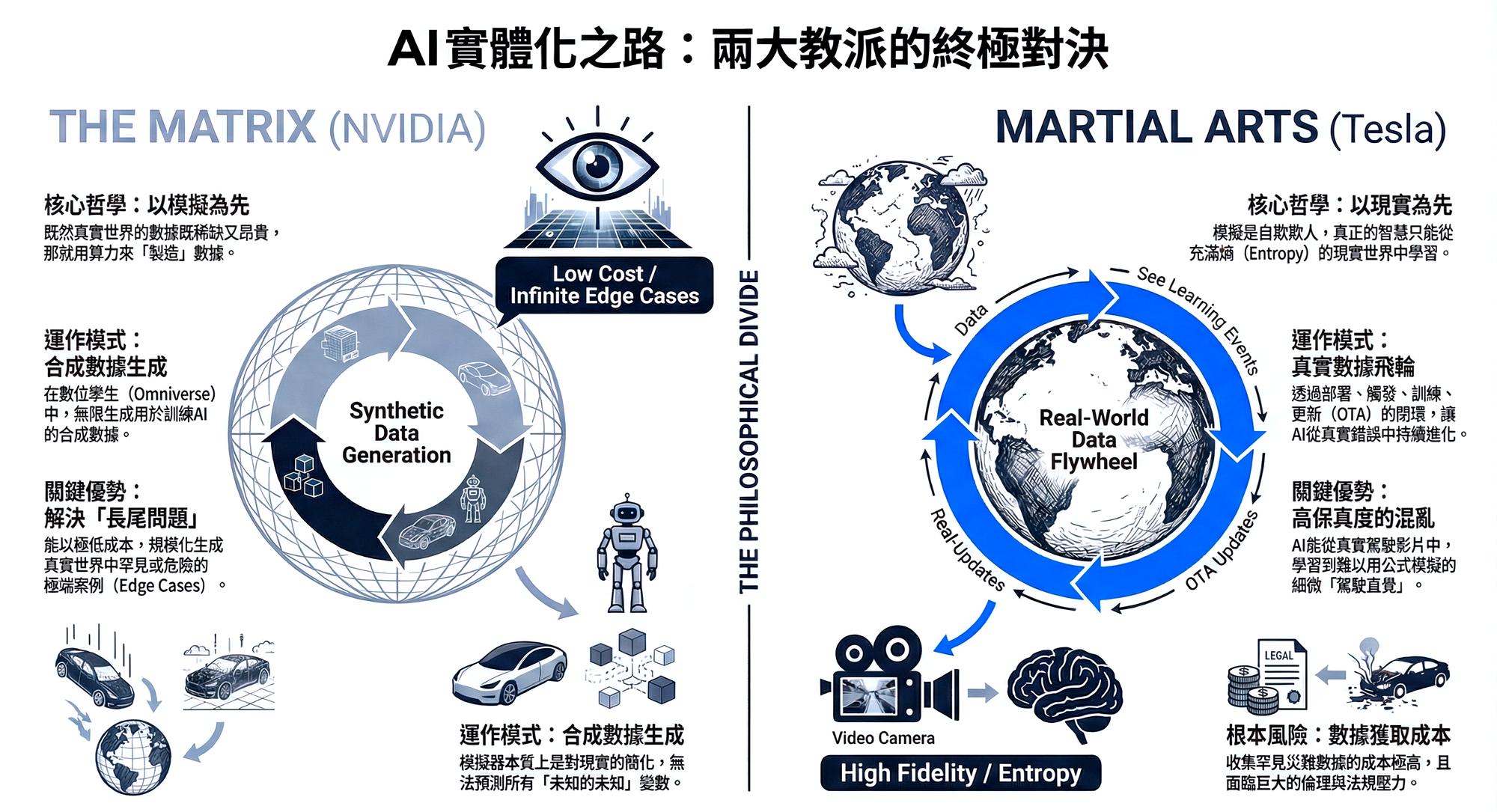
In the endgame of Physical AI, Jensen Huang and Elon Musk represent two fundamentally different worldviews. The former believes in "**The Matrix**" — that a perfect digital twin can solve everything; the latter firmly believes in "**Martial Arts**" — that only the chaos and entropy of the real world can forge true intelligence. This chapter will deeply examine the economic benefits and technical limits of these two approaches.
4.1 NVIDIA's Path: The Matrix (Simulation First)
NVIDIA's core philosophy can be summarized as: "Since real-world data is scarce and expensive, we will generate data." Through Omniverse and Cosmos, NVIDIA seeks to construct a digital twin space where physical laws are completely consistent with the real world.
Advantage Argument: Solving "The Long Tail" Real-world data distribution exhibits a normal bell curve, where 99% of driving scenarios are mundane and repetitive (e.g., driving straight on a clear highway). However, the key to AI deployment lies in the 1% of extreme cases (Edge Cases).
- Simulation's God-Eye View: In Omniverse, developers can generate "rescue missions on the Martian surface," "radiation leak repairs inside a nuclear power plant," or "100 angles of a child suddenly darting into the street." These scenarios are extremely costly to acquire in the real world, and some even involve ethical risks, but in the virtual world, the acquisition cost is solely dependent on electricity.
- Scalable Synthetic Data: As long as there is sufficient computing power (which is precisely the purpose of the Rubin architecture), synthetic data production is infinite. This solves the data hunger problem in the early stages of Physical AI development.
Risk Argument: Sim-to-Real Gap This is the Achilles' heel of the simulation approach. No matter how precise a simulator is, it is fundamentally a **reduction** of reality.
- Unknown Unknowns: Simulators can only model physical variables that engineers "know." If there are unknown unmodeled factors in the real world (e.g., a specific frequency of vibration causing a sensor to loosen, or light scattering under specific fog conditions), an AI trained perfectly in simulation might make catastrophic misjudgments upon deployment in reality.
4.2 Tesla/xAI's Path: Martial Arts (Real-World Testing First)
Elon Musk's philosophy is the complete opposite: "Simulation is self-deception; the real world is full of entropy that cannot be perfectly described by mathematics." Tesla's FSD (Full Self-Driving) and Optimus robots take an extremely hardcore "End-to-End" approach.
Advantage Argument: High-Fidelity Entropy The real world is full of noise, and this noise is precisely the breeding ground for intelligence.
- Video In, Controls Out: Tesla's neural networks no longer rely on human-written rules (e.g., see red light → stop), but directly consume billions of miles of real driving footage. The AI learns from the subtle micro-operations, hesitations, and intuitive reactions to sudden situations observed in human drivers in these videos. These subtle "driving intuitions" are very difficult to encode into physical formulas in a simulator.
- The Closed-Loop Data Flywheel: This is Tesla's strongest moat, a barrier difficult for other competitors to replicate. This cycle involves four steps:
- Deploy: Millions of vehicles driving on the road.
- Trigger: When drivers disengage or specific events occur, data is sent back.
- Train: New models are trained on real failure cases using cloud supercomputers (Dojo/Cortex).
- Update (OTA): New models are pushed back to the fleet via Over-the-Air updates and immediately receive feedback. This cycle makes the AI smarter with each turn, and the marginal cost decreases as the fleet scales.
Risk Argument: Nonlinear Acquisition Costs Collecting rare disaster data in the real world often means waiting for disasters to actually happen. This faces immense regulatory pressure in terms of ethics and legality.
4.3 Key Insight: The Broken Feedback Loop
This is the most profound concern of this report regarding NVIDIA's model, and a blind spot often overlooked by the market.
While NVIDIA provides the most powerful brains (Thor/Rubin chips) and the best training ground (Omniverse), it **does not own the body**.
- Data Sovereignty Dilemma: NVIDIA sells chips to Mercedes-Benz, Hyundai, or BYD. But will these car manufacturers freely and immediately send back the valuable real-world data (Corner Cases) collected on the road to NVIDIA to optimize their foundation models? The answer is no. Car manufacturers will treat data as proprietary assets.
- Strategic Necessity: This explains why NVIDIA must stick to the "simulation path." Because it cannot, like Tesla, have an inexhaustible data faucet of real-world data. For NVIDIA, **Simulation is not a choice, it is a necessity**.
4.4 Non-Technical Barriers: Regulation and Ethics (The Non-Technical Moat)
Beyond technology, the two paths face different societal resistances.
- Tesla's Challenges: Public safety and privacy. The practice of using public roads as a Beta testing ground faces increasingly stringent regulatory scrutiny (e.g., NHTSA). Furthermore, real video footage involves the privacy of passersby, and the compliance costs of processing such data are extremely high.
- NVIDIA's Challenges: Algorithmic Bias. If in a simulated environment, pedestrian model data lacks diversity (e.g., primarily adults, lacking children or disabled individuals), the trained AI may develop blind spots in identification for specific groups in the real world.
4.5 Endgame Prediction: Industry Stratification (The Endgame)
We believe that this battle will not have only one winner but will lead to a stratification of the industry structure:
- NVIDIA becomes the "iOS of Physical AI": It will empower 90% of enterprises. Logistics companies, warehouse automation manufacturers, and traditional car manufacturers, unable to build vast data centers and simulation environments themselves, will rely on NVIDIA's Omniverse platform and pre-trained models (GR00T) to develop products. NVIDIA will collect an "Infrastructure Tax."
- Tesla becomes a "Vertical Giant": Like Apple, Tesla, through software-hardware integration and its proprietary real-world data closed loop, will dominate high-margin, high-difficulty vertical domains such as "general-purpose humanoid robots" and "L4/L5 autonomous driving." Its product experience will be closed but ultimate.
Chapter Five: Macro Constraints — Singularity, Energy & Geopolitics
Macro Constraints: Energy, Singularity & Geopolitics
The exponential growth of technology will eventually hit the linear boundaries of the physical world. This chapter explores the Hard Constraints that cannot be solved by programming. For long-term investors, focusing on "who owns transformers" may be more critical than "who owns GPUs."
5.1 The Singularity Timeline: The Failure of Valuation Models (The Singularity Timeline)
During CES, Elon Musk reiterated his aggressive prediction for **AGI (Artificial General Intelligence)**: human intelligence will be surpassed by 2029. If the market starts to seriously factor this "singularity" into pricing, traditional financial valuation models will face collapse.
- Failure of DCF (Discounted Cash Flow): Traditional DCF models are based on linear or gently exponential growth forecasts of future cash flows. However, once Physical AI can massively replace human labor (e.g., Optimus robots cost less than human wages), productivity growth will show a vertical curve.
- Panic Migration of Capital: In anticipation of an approaching singularity, capital will no longer chase assets that "make money through labor" (such as traditional service industries), but will frantically flow into assets that "can generate labor." This explains why, even with extremely high PE Ratios, capital continues to pour into NVIDIA (producing brains) and Tesla (producing bodies) — investors are not buying growth stocks, but tickets to a new economic system.
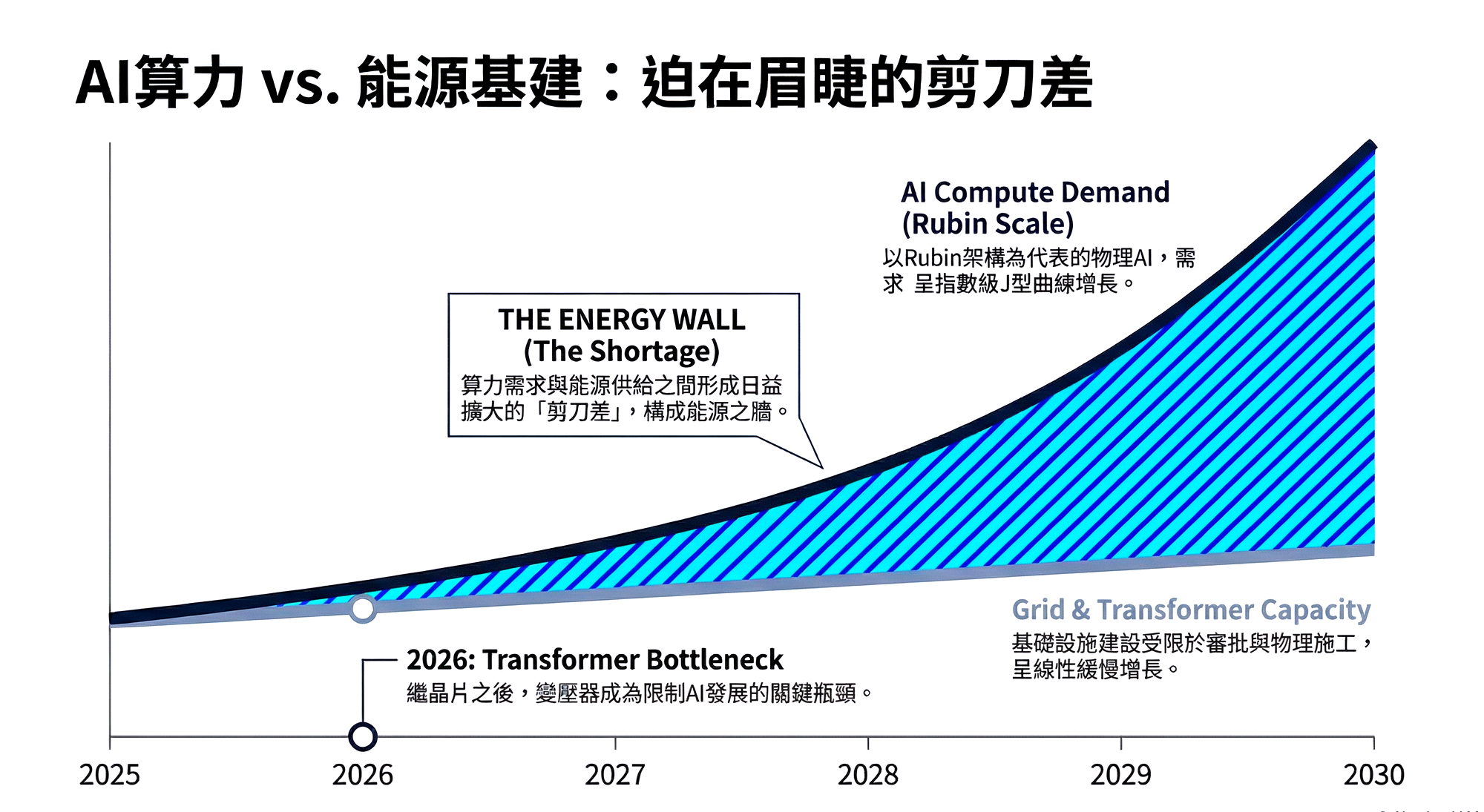
5.2 The Energy Wall: The Compute-Power Scissors Gap (The Energy Wall)
This is the risk variable this report most strongly recommends focusing on. While Jensen Huang's Rubin architecture significantly improves Performance per Watt, the growth rate of physical simulation demand far outpaces this. We are facing a severe "compute-power scissors gap."
- Not a Chip Shortage, a Transformer Shortage: Elon Musk astutely pointed out that the bottleneck in the next two years will shift from silicon chips to **Voltage Transformers** and **Step-down Stations**. Building a 100MW data center takes years for grid approval and substation construction, while deploying chips only takes months. This Timing Mismatch will lead to a large number of shipped GPUs being temporarily unable to go online.
- Winners and Losers: In the era of "Power-Constrained Compute," competitive advantages have shifted:
- Winners: Hyperscalers with "self-built energy capabilities" or "priority grid negotiation rights" (e.g., Microsoft's nuclear energy布局, Amazon purchasing nuclear power sites). And companies like Tesla, with SolarCity and Megapack energy storage businesses, because they can build off-grid computing centers.
- Losers: Small and medium-sized data centers and pure software companies that rely solely on the public grid and lack energy negotiation leverage.
5.3 Geopolitics and Supply Chain Resilience
While we have discussed many futures for cloud and software, the physical foundation of Physical AI remains highly concentrated in East Asia.
- Geographic Concentration of CoWoS: The CoWoS-L packaging and HBM4 memory stacking that the Rubin architecture relies on have critical production capacity extremely dependent on TSMC and SK Hynix. Although the CHIPS Act attempts to diversify risk, the focus of high-end packaging will remain in Taiwan until at least 2028.
- Risk Exposure of the Two Paths:
- NVIDIA: As a pure chip designer, its supply chain resilience is entirely dependent on TSMC's capacity allocation and geopolitical security.
- Tesla: While its chips rely on TSMC, its robotics and automotive manufacturing are highly vertically integrated, and its factories are spread globally (USA, China, Germany). Relatively speaking, Tesla possesses higher autonomy and fault tolerance in its "physical end-product" supply chain.
Chapter Six: Conclusion & Investment Thesis
The Verdict: Allocating Capital in the Age of Physical AI
2026 is not just a turning point for AI technology, but also a period of re-evaluation for AI investment logic. The past three years' crude strategy of "buying any company vaguely related to LLMs" is no longer applicable. Capital is retreating from the "model layer" and shifting towards "energy," "physical end-devices," and "closed ecosystems." This chapter will provide a detailed capital allocation blueprint.
6.1 Value Chain Reconstruction: The AI "Smile Curve" (The New Smile Curve)
In the Generative AI era, value was once concentrated in the central "Model Layer." But in the Physical AI era, we predict the value chain will evolve into a deep "smile curve," where profits will be extremely squeezed towards both ends, while the middle layer will face a bloody commoditization red ocean.
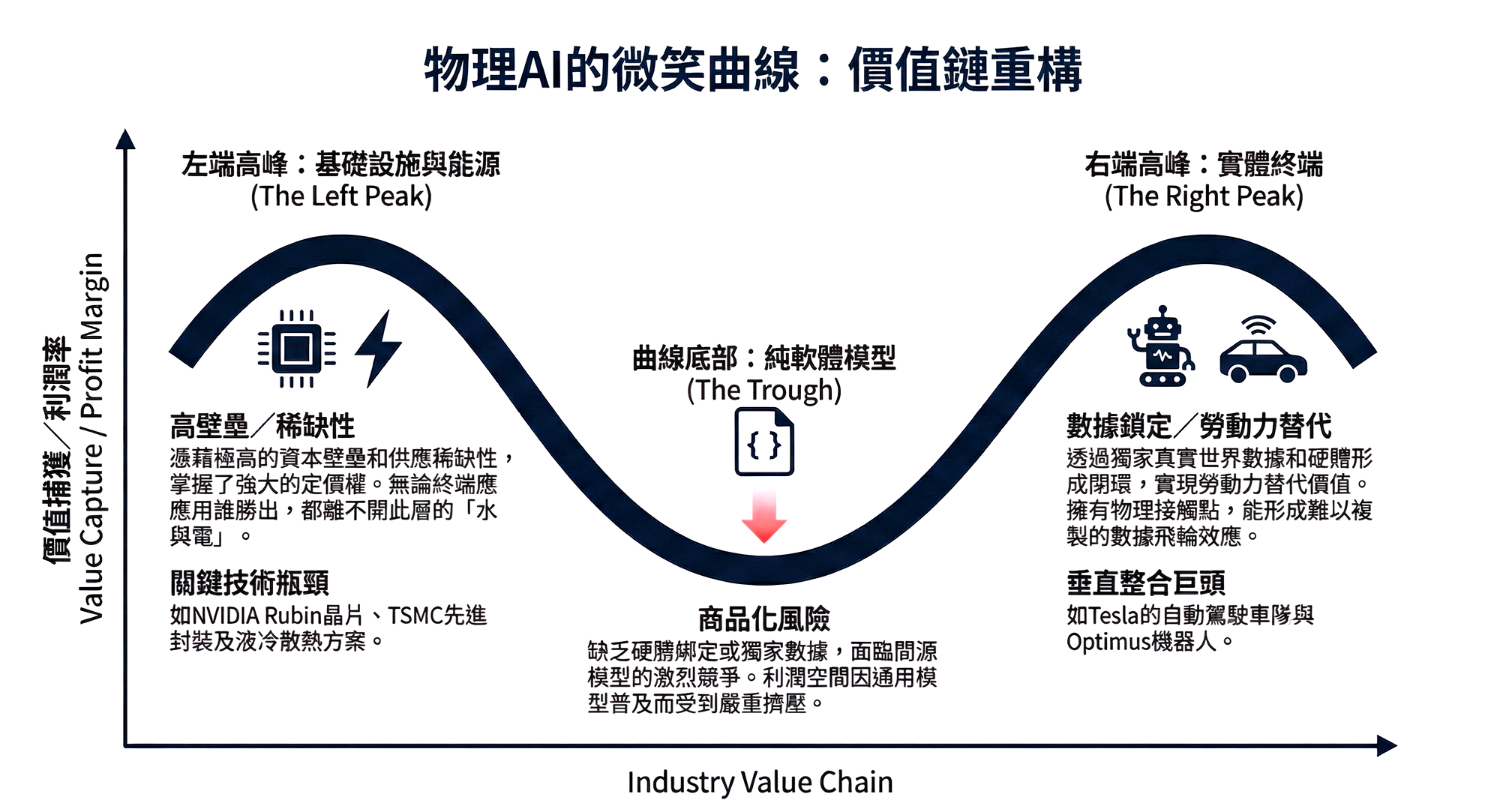
- Left End: Infrastructure & Energy
- Characteristics: Extremely high capital barriers, limited supply.
- Logic: This is the "water and electricity" for Physical AI. Regardless of whose robots prevail, they will need Rubin chips for training, liquid-cooled racks for heat dissipation, and stable green power to operate. This layer commands the strongest **Pricing Power**.
- Right End: Physical Edge & Closed Applications
- Characteristics: Owns proprietary data, high customer stickiness.
- Logic: Tesla's fleet, Intuitive Surgical's surgical robots, Deere's agricultural machinery. These companies have "physical touchpoints" and can form data closed loops. Value lies in the direct revenue generated by "labor substitution."
- Bottom: Pure Software Model Layer (The Middle Squeeze)
- Risks: As open-source models (like VLA) approach the capabilities of closed-source models, software companies that merely provide "general-purpose robot brains" but lack hardware binding or proprietary data will face **Margin Compression**.
6.2 Core Investment List (The Alpha List)
Based on the logic above, we categorize investment targets into three strategic baskets:

Basket One: The Kingmakers
These companies set the rules; others simply follow.
- NVIDIA (NVDA):
- Investment Thesis: Do not view NVIDIA merely as a chip company; it is the "digitalization platform of the physical world." The Rubin architecture + CUDA + Omniverse constitute the iOS of the robotics industry. As long as someone wants to build a robot, NVIDIA will collect a tax.
- Catalysts: HBM4 capacity ramp-up, confirmed Rubin rack-level orders, expansion of Project GR00T partnership list.
- Tesla (TSLA):
- Investment Thesis: It is the only vertically integrated giant that has successfully created a closed loop of "perception-decision-execution." The licensing model for FSD and the mass production of Optimus will lead to its re-evaluation from a "car manufacturer" to a "Labor-as-a-Service provider."
- Catalysts: FSD deployment in China/Europe, data release on Optimus substantially replacing human labor in factories.
Basket Two: The Bottlenecks & Pick-and-Shovels
These companies solve physical limitations and have irreplaceable technological strongholds.
- Energy Management (Thermal & Power):
- Targets: Vertiv (VRT), Eaton (ETN), Schneider Electric.
- Logic: The thermal density of the Rubin architecture is 3 times that of its predecessors. Liquid Cooling and high-voltage power distribution are no longer optional but essential. The order visibility for these companies is even longer than for chip manufacturers.
- Advanced Memory (High Bandwidth Memory):
- Targets: SK Hynix, Micron (MU).
- Logic: The hunger for bandwidth in physical simulation is insatiable. HBM4's Logic Stacking technology increases manufacturing difficulty and solidifies the oligopolistic structure. HBM will remain in a **Shortage** state.
- Advanced Packaging (Foundry & Packaging):
- Targets: TSMC (TSM).
- Logic: CoWoS-L is the physical foundation of Rubin's existence. TSMC is the only architect capable of assembling these building blocks.
Basket Three: The Vertical Specialists
Possessing real-world data in specific domains that cannot be simulated.
- Targets: Intuitive Surgical (ISRG), Deere & Company (DE).
- Logic: While NVIDIA provides a general-purpose brain, "how to excise a tumor" or "how to harvest lodged corn" requires extremely specialized Domain Knowledge and data. The moats of these companies in their vertical domains are difficult for general AI to breach.
6.3 The Avoid List: Risk Assets to Steer Clear Of
Investing is not just about offense, but also defense. In the Physical AI boom, it is advisable to reduce holdings or observe the following types of assets:
- Pure Software AI Wrappers:
- Startups that lack underlying model R&D capabilities and merely connect APIs to control robots. They are highly susceptible to being replaced by NVIDIA's free tools (GR00T) or open-source models.
- Energy-Poor Colocation Data Centers:
- Small and medium-sized data centers that rely on the public grid, are located in power-constrained regions, and cannot expand capacity. They will be unable to accommodate Rubin-level supercomputing hosting demands and face customer attrition.
- Automotive Chipmakers Reliant on Older Generation Processes:
- As high-end chips with "reasoning capabilities" like Alpamayo become more prevalent, traditional MCU manufacturers that can only handle simple rule-based logic will face value erosion.
6.4 Key Metrics to Watch: How to Verify Success or Failure?
Investors should stop focusing on "model parameter count," a vanity metric, and instead pay attention to the following **substantive indicators**:
- Cost per Simulated Hour:
- Has NVIDIA's Rubin truly reduced simulation costs to 1/10000 of real-world testing? This is the economic prerequisite for mass adoption.
- Disengagement Rate:
- For Tesla FSD and robots, how many hours of driving/operation require human intervention? This is the only truth to verify whether the Sim-to-Real gap has been bridged.
- Energy Intensity:
- Data center PUE (Power Usage Effectiveness) and energy consumption per unit of compute power. This determines the physical boundary of AI expansion.
6.5 The Final Word: The Power to Digitize Reality
CES 2026 tells us that the next chapter of AI is not about generating text, but about **reshaping physical productivity**.
The essence of this competition is the struggle for "**The Power to Digitize Reality**."
- NVIDIA attempts to "compute" a perfect physical world using computational power.
- Tesla attempts to "record" a real physical world using data.
For investors, this is not a black-and-white choice. In the short term (1-3 years), Tesla's real-world data offers a monopolistic advantage in solving edge cases; in the long term (3-5 years), NVIDIA's simulation ecosystem is the only solution to data scarcity.
The ultimate recommendation is: Overweight infrastructure stocks that provide the "pick-and-shovels" (NVIDIA/HBM/Energy), and strategically hold end-application stocks that can demonstrate ownership of a "data flywheel" (Tesla/Verticals). As for the middle layer, exercise extreme caution.

![[Industry Capital Flows Weekly] 20260309 Capital Reallocation and Micro-level Capital Flow Divergence in AI Infrastructure](/content/images/size/w1200/2026/03/Gemini_Generated_Image_9yzcdz9yzcdz9yzc-1.png&q=100)
![[Industry Capital Flows Weekly] 20260215 Capitalizing on AI Specification Bonuses, Avoiding Equipment Makers' Book-Closing Sell-off](/content/images/size/w1200/2026/03/Gemini_Generated_Image_mq6ktymq6ktymq6k-1.png&q=100)
